Task-level success rates for four single-arm and two dual-arm tasks. HarmoWAM achieves the best average result.
| Method | Pick Fruit | Stack Cans | Pour Coke | Write "Yes" | Put Flowers | Put Items | Average |
|---|---|---|---|---|---|---|---|
| π0.5 | 0.80 | 0.68 | 0.75 | 0.83 | 0.72 | 0.67 | 0.74 |
| VPP | 0.80 | 0.60 | 0.78 | 0.73 | — | — | 0.73 |
| Wan+AnyPos | 0.88 | 0.60 | 0.78 | 0.72 | 0.53 | 0.52 | 0.67 |
| QwenVLA-OFT | 0.78 | 0.30 | 0.73 | 0.72 | — | — | 0.63 |
| Cosmos-Policy | 0.93 | 0.65 | 0.80 | 0.83 | 0.75 | 0.72 | 0.78 |
| HarmoWAM (Ours) | 0.95 | 0.90 | 0.88 | 0.92 | 0.85 | 0.85 | 0.89 |
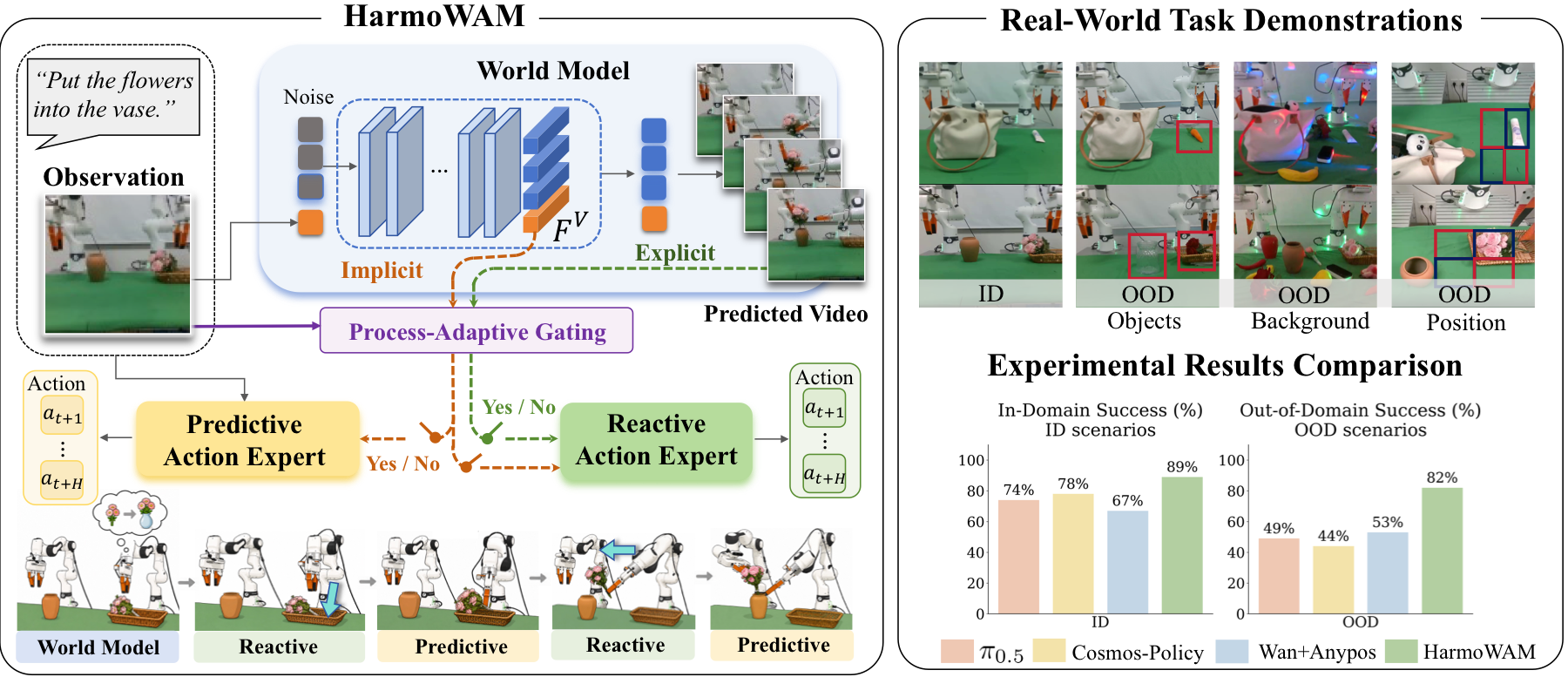
HarmoWAM uses world-model predictions to expand exploration space, helping the robot reach target objects under unseen backgrounds, positions, and object instances.
The predictive expert conditions on latent video dynamics, supporting temporally coherent actions for contact-rich interaction and bimanual coordination.
Process-Adaptive Gating routes control between reactive and predictive experts according to the current task stage, forming a unified closed-loop WAM policy.
HarmoWAM maintains strong zero-shot performance across three OOD scenario types.
| Method | Background | Position | Objects | Global Avg | Drop from ID |
|---|---|---|---|---|---|
| π0.5 | 0.60 | 0.32 | 0.54 | 0.49 | 33.8%↓ |
| VPP | 0.43 | 0.23 | 0.57 | 0.41 | 43.8%↓ |
| Wan+AnyPos | 0.53 | 0.49 | 0.58 | 0.53 | 20.9%↓ |
| QwenVLA-OFT | 0.46 | 0.28 | 0.50 | 0.41 | 34.9%↓ |
| Cosmos-Policy | 0.57 | 0.26 | 0.50 | 0.44 | 43.6%↓ |
| HarmoWAM (Ours) | 0.81 | 0.80 | 0.85 | 0.82 | 7.9%↓ |
HarmoWAM is evaluated on six real-world manipulation tasks, including four single-arm tasks and two dual-arm collaborative tasks.
World Action Models (WAMs) have emerged as a promising paradigm for robot control by modeling physical dynamics. Current WAMs generally follow two paradigms: the "Imagine-then-Execute" approach, which uses video prediction to infer actions via inverse dynamics, and the "Joint Modeling" approach, which jointly models actions and video representations.
Based on systematic experiments, we observe a fundamental trade-off between these paradigms: the former explicitly leverages world models for generalizable transit but lacks interaction precision, whereas the latter enables fine-grained, temporally coherent action generation but is constrained by the exploration space of the training distribution.
Motivated by these findings, we propose HarmoWAM, an end-to-end WAM that fully leverages a world model to unify predictive and reactive control, enabling both generalizable transit and precise manipulation. A Process-Adaptive Gating Mechanism automatically determines the timing and location of switching between complementary experts. Across six real-world tasks and three training-unseen test environments, HarmoWAM significantly outperforms prior state-of-the-art VLA models and WAMs.
@misc{harmowam2026,
title = {HarmoWAM: Harmonizing Generalizable and Precise Manipulation via Adaptive World Action Models},
author = {Feng, Qiuxuan and Yu, Jiale and Liu, Jiaming and Jia, Yueru and Wu, Zhuangzhe and Chen, Hao and Qian, Zezhong and Gu, Shuo and Jia, Peng and Ma, Siwei and Zhang, Shanghang},
year = {2026}
}